
Our product development and engineering team has been working hard over the last 5 months.
It is our true pleasure to announce that SitScape’s latest software release of version of 3.1.9.6 is available today!
Continuing our product innovation as well as enhanced quality control, release 3.1.9.6 is our latest release with significant improvements and useful features based on the excellent feedback of our various customers including Fortune -100 customers.
Here I would like to highlight one specific powerful new feature coming out of this SitScape new release – Straight-Through-Processing (STP) to easily automate processes and workflows from Data Ingestion; to Data Preparation such as ETL, to Data Processing such as filtering, enrichment, aggregation, merging, fusion; to rule-based Operational Alerting and Incident Tracking; to easy-to-use and rapid-fire Visualization and self-service Analytic and Exploratory Data Discovery; also to advanced Data Correlation!
[Use Case]
How can your automate data processing and visualization of a multi-step process that involves various operations such as ingestion, ETL steps, with data coming from multiple sources (real-time or historical), and in many cases that source data is dynamic and updated over time instead of static?
[How-To]
The Straight-Through-Processing (STP) module in SitScape can support user-defined, repeatable, automated multi-step processes on Data Ingestion, Preparation, Transformation, Analysis, Visualization, Correlation, Alert and Reporting with on-demand action or scheduled workflow.
It has a graphic drag-and-drop front-end interface allowing user-defined STP process creation and configuration; and is powered by a server-side STP engine enabling data ingestion, various data ETL, data fusion, data visualization, monitoring and alert and can triggered on-demand or by a scheduler. It can handle large data set in batch mode. It supports testing-run, preview, and deployment modes of such STP processes.
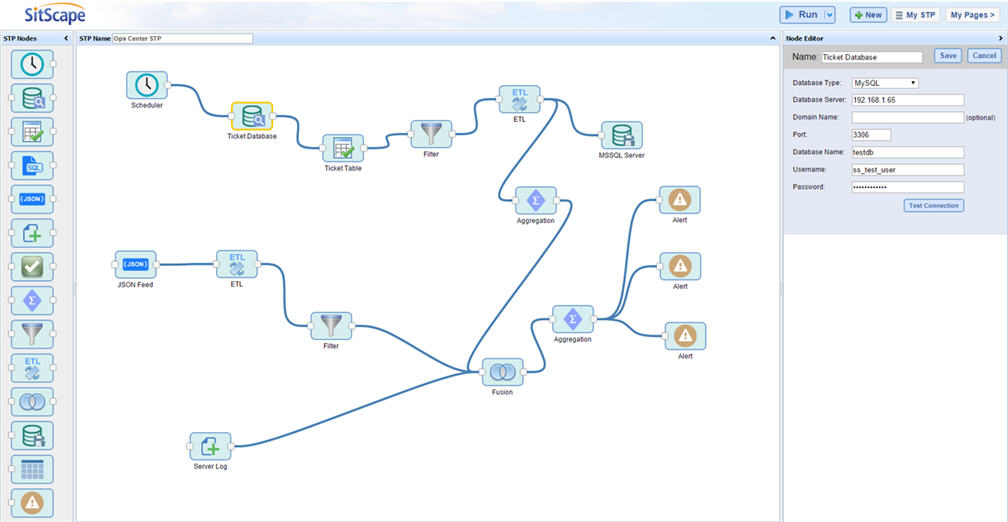
[Screen Sample]
Showing below is a sample screen shot of the STP configuration. The basic concept here is that a STP process is composed of multiple “Nodes” in a canvas, with each Node being a processing-unit such as connect to a database or a Web Service, do a filter, do a series of ETL transformation , do a statistical aggregation, do a data fusion etc. and the process runs from the left to the right on the nodes as multiple “pipelines”, and a STP process can be run on-demand, or driven by a user-defined schedule to re-run again and again on a regular basis for automated data processing and workflows.




{kind=link}
{kind=link}
{kind=link}